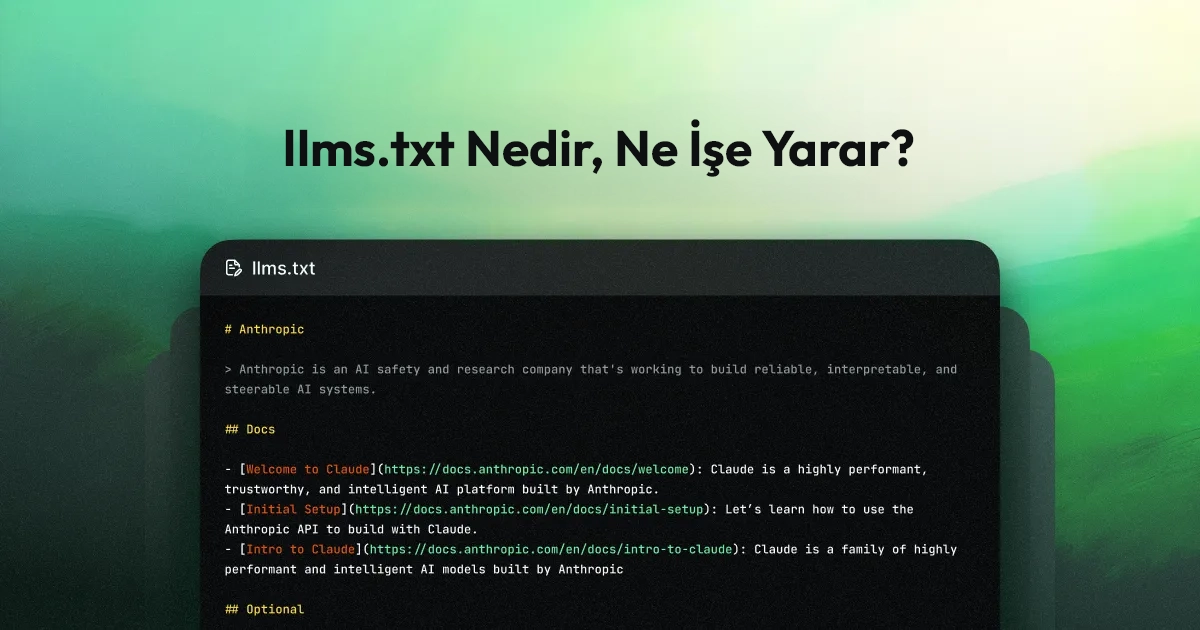
llms.txt, web sitelerinin içeriklerini LLM’lere daha okunabilir ve yönlendirilmiş biçimde sunmak için önerilen, ancak henüz evrensel standart haline gelmemiş bir dosya yaklaşımıdır.
Yapay zekâ destekli arama ve cevap sistemleri büyüdükçe, web site sahipleri de şu soruyu daha sık sormaya başladı: İçeriğimi LLM’lere daha iyi nasıl anlatabilirim? İşte llms.txt tam bu ihtiyacın etrafında doğan yeni bir fikir. En kısa tanımıyla llms.txt, bir sitenin önemli içeriklerini, bağlamını ve önceliklerini LLM’lere daha sade ve yönlendirilmiş biçimde sunmak için önerilen bir dosya formatıdır. Bu fikir, Jeremy Howard tarafından Eylül 2024’te “/llms.txt” önerisi olarak yayımlandı ve doğrudan “LLM’lerin bir siteyi inference time’da daha iyi kullanmasına yardım etmek” amacıyla tanımlandı.
Ama burada çok kritik bir ayrım var: llms.txt bugün için resmî, evrensel ve zorunlu bir web standardı değildir. Daha doğru ifade şu olur: Bu bir topluluk önerisidir. Yani bazı şirketler ve dokümantasyon siteleri bunu uygulamaya başladı, fakat bu dosyanın tüm büyük arama sistemleri ve tüm LLM sağlayıcıları tarafından aynı şekilde işlendiğini varsaymak doğru olmaz. Özellikle Google tarafında, AI Overviews ve AI Mode için ekstra teknik gereklilik olmadığı açıkça belirtiliyor; normal SEO en iyi uygulamalarının geçerli olduğu söyleniyor.
llms.txt Tam Olarak Nedir?
llms.txt, genellikle sitenin kök dizininde bulunan ve Markdown benzeri sade metin yapısıyla yazılan bir dosyadır. Temel amacı, sitenizdeki en önemli kaynakları LLM’lerin daha kolay anlamasına yardımcı olacak şekilde özetlemek, sınıflandırmak ve öne çıkarmaktır. Önerinin resmî açıklamasında bu dosyanın; kısa arka plan bilgisi, yönlendirme ve daha detaylı Markdown dosyalarına bağlantılar içerebileceği söylenir. Yani mantık şudur: “Sitem büyük ve karmaşık olabilir; ama eğer bir LLM içeriklerimi kullanacaksa, önce şu çerçeveyi ve şu kaynakları görsün.”
Bunu daha somut düşünelim. Mesela çok kapsamlı bir SaaS dokümantasyon sitesi yönetiyorsunuz. Ana sitede yüzlerce sayfa, sürüm farkları, changelog’lar, örnek kodlar, pazarlama içerikleri ve blog yazıları olabilir. llms.txt ile bu yapının içinden “ürünün temel açıklaması”, “kurulum rehberi”, “API referansı”, “fiyatlandırma”, “güvenlik”, “en güncel doküman seti” gibi en önemli alanları öne çıkarabilirsiniz. Böylece LLM açısından sitenin “öncelikli okuma haritasını” vermiş olursunuz. Bu kullanım mantığı, OpenAI ve Anthropic’in kendi dokümantasyon sitelerinde sundukları llms.txt ve llms-full.txt yapılarında da pratik olarak görülüyor.
llms.txt Ne İşe Yarar?
llms.txt’nin en güçlü kullanım alanı, içeriği daha “LLM-friendly” hale getirmektir. Yani amaç, LLM’in sitenizde neyin önemli olduğunu daha hızlı görmesi, doğru kaynağa daha çabuk gitmesi ve özellikle karmaşık dokümantasyon veya bilgi mimarilerinde daha az dağılmasıdır. Öneri metninde de dosyanın, LLM dostu içerik sunmak için kısa arka plan bilgisi, yönlendirme ve detaylı Markdown kaynaklarına bağlantılar sağlayacağı belirtilir.
Bunu bir örnekle açalım. Diyelim ki bir yapay zekâ ajanı sizin geliştirici dokümantasyon sitenizi kullanarak kullanıcıya cevap verecek. Eğer sitenizde onlarca sürüm, eski rehber, pazarlama sayfası ve API içeriği karışık haldeyse, ajan yanlış ya da eski kaynağa gidebilir. Ama kökteki llms.txt dosyanız “güncel API dokümanları burada”, “eski sürümler şurada”, “hızlı başlangıç sayfası bu”, “tam Markdown export dosyası burada” gibi çok net bir yol gösteriyorsa, bu dosya ajan için ciddi pratiklik sağlayabilir. Bu yüzden llms.txt özellikle bilgi yoğun sitelerde “içerik önceliklendirme katmanı” gibi düşünülebilir.
llms.txt Ne İşe Yaramaz?
Bu kısım en az “ne işe yarar” kadar önemli. llms.txt, robots.txt gibi bağlayıcı bir erişim kontrol mekanizması değildir. Yani “şu bot girebilir, şu bot giremez” mantığıyla çalışmaz. Crawl kontrolü için bugün hâlâ robots.txt ve ilgili user-agent kuralları kullanılır. Google’ın robots.txt rehberi de kuralların zaten zorlayıcı değil, gönüllü uyulan kurallar olduğunu; ayrıca robots.txt’nin güvenlik mekanizması olmadığını açıkça söyler. OpenAI da kendi crawler dokümantasyonunda GPTBot ve OAI-SearchBot için robots.txt user-agent kontrollerini resmî yöntem olarak anlatır.
Aynı şekilde llms.txt, Google’da AI Overviews’a girmek için gereken özel bir sinyal değildir. Google Search Central, AI özellikleri için ek teknik gereklilik olmadığını, klasik SEO en iyi uygulamalarının yeterli olduğunu açıkça belirtiyor. Sektörde Gary Illyes’in Google’ın llms.txt’yi desteklemediği yönündeki açıklamaları da geniş biçimde raporlandı; ancak burada en güvenilir dayanak yine Google’ın resmî dokümanıdır: AI Overviews ve AI Mode için “ek optimizasyon gerekmez”. Bu yüzden llms.txt’yi bir Google sıralama ya da AI Overview optimizasyon dosyası gibi düşünmek doğru olmaz.
Bir başka önemli nokta da şu: llms.txt tek başına “beni cite et” butonu değildir. Yani dosyayı oluşturmanız, her LLM’in sitenizi okuyacağı, sizi daha çok kaynak göstereceği ya da içeriklerinizi mutlaka o dosyaya göre işleyeceği anlamına gelmez. Bugün için en dürüst yaklaşım şudur: llms.txt yardımcı olabilir, ama garanti vermez. Bunun nedeni de dosyanın henüz evrensel şekilde benimsenmiş, zorunlu ya da standartlaşmış bir protokol olmamasıdır.
robots.txt, sitemap.xml ve llms.txt Arasındaki Fark Nedir?
robots.txt ile llms.txt en sık karıştırılan iki dosyadır. robots.txt bir tarama kontrol dosyasıdır. Hangi botun nereye gidebileceğini veya gidemeyeceğini söyler. Ama robots.txt bile tüm botları zorla durdurmaz; uyum botun insiyatifindedir. Google bu sınırlamayı kendi rehberinde açıkça anlatır.
sitemap.xml ise kapsam bildirir. Yani sitenizde hangi URL’lerin önemli olduğunu ve indekslenmesini istediğinizi arama motoruna topluca bildirirsiniz. Bu dosya “hangi sayfalar var?” sorusuna cevap verir. llms.txt ise daha çok “hangi içeriklere öncelik verilmeli, bu sitenin mantığı nedir, hangi kaynaklar öne çıkarılmalı?” sorusuna cevap vermeye çalışır. Bir anlamda sitemap kapsamı gösterir, llms.txt ise öncelik ve bağlam vermeye çalışır. Bu yüzden llms.txt, sitemap’in yerine geçmez; robots.txt’nin de yerine geçmez. En doğru bakış, onu üçüncü ve daha açıklayıcı bir katman gibi düşünmektir.
llms.txt Kimler İçin Daha Faydalıdır?
Her site için aynı derecede gerekli değildir. En çok değer üretebileceği yerler, içerik yapısı karmaşık olan ve gerçekten “kaynak rehberi” ihtiyacı duyan sitelerdir. Özellikle geliştirici dokümantasyonları, API dokümanları, bilgi tabanları, eğitim platformları, kapsamlı yardım merkezleri ve büyük SaaS siteleri llms.txt’den daha fazla fayda görebilir. Çünkü bu yapılarda içerik çoktur, sürümler olabilir, eski ve yeni kaynaklar iç içe geçebilir ve bir ajanın yanlış sayfaya gitme ihtimali artar. OpenAI ve Anthropic’in kendi dokümanlarında llms.txt / llms-full.txt benzeri kaynaklar sunuyor olması da bu kullanım senaryosunu güçlendiriyor.
Buna karşılık beş sayfalık küçük bir kurumsal sitede, sadece birkaç hizmet sayfası ve iletişim alanı varsa llms.txt çok öncelikli iş olmayabilir. O senaryoda klasik SEO, temiz bilgi mimarisi, iyi başlık yapısı, indekslenebilir içerik, güçlü snippet kontrolü ve gerekiyorsa AI crawler’lar için robots.txt yönetimi çok daha kritik olabilir. Özellikle Google görünürlüğü hedefleyen sitelerde Google’ın kendi tavsiyesi zaten normal SEO uygulamalarını sürdürmektir.
llms.txt Nasıl Oluşturulur?
Temel prensip basittir: Kök dizinde, sade ve okunabilir bir dosya yayınlanır. Genellikle adres şu olur:
https://alanadiniz.com/llms.txt
Öneri metninde bu dosyanın Markdown tabanlı, hem insan hem LLM tarafından okunabilir ama aynı zamanda düzenli şekilde parse edilebilir bir formatta olması hedeflenir. Bu yüzden pratikte başlıklar, kısa açıklamalar ve bağlantı listeleri kullanılır.
İyi bir llms.txt dosyasında genelde şu alanlar bulunur:
İlk bölümde sitenin ne olduğu kısa ve net anlatılır.
İkinci bölümde en önemli içerik kümeleri listelenir.
Üçüncü bölümde kritik kaynaklara doğrudan bağlantı verilir.
İmkân varsa daha detaylı tek dosya export için llms-full.txt ya da Markdown doküman arşivi sunulur.
Eski sürümler, deprecated dokümanlar veya yalnızca arşiv amaçlı alanlar ayrıca not edilir.
Basit Bir llms.txt Örneği
Aşağıdaki örnek, sade ama işlevsel bir yapıyı gösterir:
# Fabrikido
Fabrikido, SEO, web tasarım, performans optimizasyonu ve dijital reklam yönetimi alanlarında hizmet veren bir dijital ajanstır.
## En önemli sayfalar
- Ana sayfa: https://www.fabrikido.com/
- SEO hizmetleri: https://www.fabrikido.com/seo-hizmetleri
- Google Ads danışmanlığı: https://www.fabrikido.com/google-ads-danismanligi
- Web tasarım hizmetleri: https://www.fabrikido.com/web-tasarim
- Blog: https://www.fabrikido.com/blog
## Rehber içerikler
- WordPress hızlandırma rehberi: https://www.fabrikido.com/blog/wordpress-hizlandirma-rehberi
- Core Web Vitals rehberi: https://www.fabrikido.com/blog/core-web-vitals-nedir
- Yerel SEO rehberi: https://www.fabrikido.com/blog/yerel-seo-nedir
## Notlar
- Öncelikli kaynaklar yukarıdaki rehber içeriklerdir.
- Blog içindeki eski ve güncelliğini yitirmiş yazılar ikincil önemdedir.
- Hizmet açıklamalarında en güncel bilgi hizmet sayfalarındadır.
Bu örnekte gördüğün şey, bir izin sistemi değil; bir öncelik ve bağlam dosyasıdır. Yani LLM’e “sitemin özeti bu, önce buralara bak” diyorsun. Bu, özellikle çok sayıda içeriği olan sitelerde faydalı olabilir. Öneri metnindeki yaklaşım da tam olarak bunu hedefler.
Daha Gelişmiş Yapı Nasıl Olmalı?
Daha büyük sitelerde llms.txt’yi yalnızca link listesi gibi bırakmak yerine, içerik kümelerini bilinçli sınıflandırmak daha faydalı olur. Örneğin “Ürün Dokümanları”, “API”, “Yardım Merkezi”, “Başlangıç Rehberleri”, “Güvenlik”, “Sürüm Notları” gibi başlıklar açılabilir. Böylece LLM veya ajan, sitenin mimarisini ilk bakışta anlayabilir. Bu tarz yapıların OpenAI ve Anthropic’in doküman yaklaşımlarında da fiilen kullanıldığını görüyoruz; her ikisi de LLM için optimize edilmiş giriş indeksleri ve daha kapsamlı düz metin/Markdown export mantığı sunuyor.
Mesela bir API dokümantasyon sitesi için şöyle bir mantık kurulabilir: “Hızlı Başlangıç”, “Authentication”, “Rate Limits”, “Errors”, “Reference”, “Migration Guides”. Böylece kullanıcının bir ajan aracılığıyla sorduğu soruda modelin eski blog yazısına değil doğrudan ilgili referans dokümana gitme ihtimali artar. Bu kullanım, özellikle developer-facing sitelerde llms.txt’nin en güçlü senaryolarından biridir.
llms-full.txt Nedir?
llms-full.txt zorunlu bir dosya değil, ama pratikte sık görülen tamamlayıcı yapıdır. Mantık şu: llms.txt özet dizin görevi görür, llms-full.txt ise daha kapsamlı tek dosyalık Markdown export sağlar. OpenAI ve Anthropic’in dökümantasyonlarında böyle bir desenin kullanıldığı açıkça görülebiliyor. OpenAI API dokümanları için llms.txt bir indeks sunarken, llms-full.txt tek dosya birleşik export mantığı veriyor; Anthropic tarafında da benzer şekilde llms.txt ve llms-full.txt erişimleri yer alıyor.
Bunu bir örnekle düşünelim. llms.txt “önce şu 15 sayfaya bak” derken, llms-full.txt “istersen bu ürünün bütün doküman setini tek Markdown dosyada oku” demiş olur. Özellikle RAG, ajanlar veya dokümantasyonla çalışan sistemler için bu çok kullanışlı olabilir.
WordPress’te llms.txt Nasıl Yayınlanır?
WordPress’te en kolay yöntem, sitenin kök dizinine düz bir llms.txt dosyası koymaktır. Teknik erişimin yoksa yönlendirme veya özel endpoint mantığıyla da servis edebilirsin; ama en temiz yaklaşım doğrudan kökte 200 durum kodu dönen düz bir dosya sunmaktır. Çünkü önerinin mantığı da frictionless erişimdir: bot veya ajan geldiğinde dosyayı kolayca alabilsin. Bu gereklilik öneri metninin ruhuyla uyumludur.
Pratik bir örnek verelim. WordPress sitende /blog/, /hizmetler/, /iletisim/ gibi yapılar olabilir. llms.txt dosyanı bunların üstüne açıklayıcı bir katman gibi düşün. İçeriği elle güncelleyebilir ya da daha gelişmiş projelerde içerik tiplerinden otomatik üretebilirsin. Ama küçük ve orta ölçekli sitelerde elle hazırlanan temiz bir dosya çoğu zaman yeterlidir.
Özel Yazılım Sitelerde llms.txt Nasıl Yönetilir?
Özel yazılım projelerde avantaj daha fazla kontrol sağlamaktır. llms.txt’yi sabit dosya olarak yayınlayabilir, CMS içeriğinden otomatik üretebilir veya deploy sırasında yeniden oluşturabilirsin. Eğer doküman sitesi, bilgi tabanı veya geliştirici portalı yönetiyorsan, llms.txt ile llms-full.txt üretimini build sürecine bağlamak mantıklı olabilir. OpenAI ve Anthropic’in doküman yapılarında gördüğümüz şey de temelde budur: insan okuyucu için HTML, LLM için özet indeks ve geniş metin export.
Örneğin her yeni doküman yayına alındığında sistemin otomatik olarak “önemli kaynaklar” bölümünü güncellemesi sağlanabilir. Ama burada kritik nokta otomasyonun rastgele her URL’yi dosyaya yığmamasıdır. llms.txt’nin değeri kapsama değil, seçiciliğe dayanır.
llms.txt Oluştururken Nelere Dikkat Edilmeli?
En sık hata, bunu robots.txt gibi düşünmektir. llms.txt engelleme dosyası değildir. İkinci sık hata, sitemap gibi yüzlerce URL’yi körü körüne içine doldurmaktır. Oysa bu dosyanın gücü, “en önemli ve en doğru kaynakları” öne çıkarmasındadır. Üçüncü hata, güncel olmayan veya eski kaynakları öne koymaktır. Eğer deprecated dokümanları yukarıda, güncel olanları aşağıda bırakırsan LLM açısından rehber işlevin zayıflar.
Bir başka hata da beklentiyi fazla büyütmektir. “Bu dosyayı koydum, artık tüm AI sistemleri beni daha çok gösterecek” gibi bir varsayım bugünkü durumda gerçekçi değildir. Özellikle Google tarafında böyle bir beklenti kurmak yanlış olur; Google açıkça klasik SEO yaklaşımının geçerli olduğunu söylüyor. Crawl ve erişim kontrolü tarafında ise robots.txt hâlâ asıl araçtır; OpenAI’nin crawler rehberinde de bunu net görüyoruz.
llms.txt ile robots.txt Birlikte Nasıl Düşünülmeli?
Bence en sağlıklı model şu: robots.txt ile erişim ve crawler politikası yönetilir; sitemap.xml ile önemli URL kapsamı bildirilir; llms.txt ile de içerik önceliği ve bağlam anlatılır. Yani üçü farklı işi yapar. OpenAI özelinde GPTBot ve OAI-SearchBot gibi botların yönetimi robots.txt user-agent kurallarıyla yapılır; bu, resmî ve uygulanabilir yöntemdir. llms.txt ise bunların yerine geçen değil, varsa ek rehber katmanı olan bir dosyadır.
Mesela eğitim içeriklerinizi GPTBot’a kapatmak istiyorsanız bu kararı robots.txt ile verirsiniz. Ama aynı site içinde “eğer bir ajan bu içeriği kullanacaksa önce şu başlangıç rehberlerini ve güncel kaynakları okusun” demek istiyorsanız, bu ikinci katmanı llms.txt ile kurgulayabilirsiniz.
llms.txt SEO’ya Etki Eder mi?
Burada dürüst cevap şu: Doğrudan klasik SEO sıralama faktörü gibi düşünülmemelidir. Google için AI özelliklerine dahil olmanın ayrı teknik şartı olmadığı açıkça belirtiliyor. Bu yüzden llms.txt’yi “AI SEO hilesi” gibi sunmak doğru olmaz. Google’ın resmî duruşu, klasik SEO’nun ve people-first içeriğin geçerli olduğudur.
Ama dolaylı bir etkiden söz edilebilir: Eğer llms.txt sayesinde ajanlar veya LLM tabanlı sistemler sitendeki daha doğru kaynaklara gider, daha az yanlış sayfaya sapar ve içeriğini daha iyi özetlerse, bu durum AI yüzeylerde daha sağlıklı temsil yaratabilir. Bu doğrudan kanıtlanmış, evrensel ve garantili bir etki değildir; ama mantıksal bir yardımcı etkidir. Yani llms.txt bugün için “destekleyici yapı”, “ana büyüme motoru” değil.
llms.txt Gerçekten Yapılmalı mı?
Bence bu sorunun en doğru cevabı site tipine göre verilmeli. Eğer bilgi mimarin karmaşıksa, özellikle doküman, API, yardım merkezi veya büyük bilgi tabanı yönetiyorsan, llms.txt denemeye değer. Çünkü maliyeti düşük, potansiyel faydası anlamlı olabilir. Ayrıca OpenAI ve Anthropic gibi büyük şirketlerin bu yapıyı kendi dokümantasyonlarında kullanıyor olması, özellikle doküman odaklı siteler için iyi bir işaret.
Ama küçük bir kurumsal sitede önce yapman gereken işler çok daha temel olabilir: iyi bilgi mimarisi, temiz teknik SEO, doğru canonical yapısı, crawl kontrolü, güçlü hizmet sayfaları, FAQ ve schema, hızlı mobil deneyim, kaliteli içerik ve gerekiyorsa AI crawler’lar için robots.txt yönetimi. Bu temel işler bitmeden llms.txt’yi birincil öncelik yapmak çoğu zaman doğru sıra olmaz. Google tarafında da zaten temel SEO’nun yeterli olduğu vurgulanıyor.
Kısaca Özetlemek Gerekirse
llms.txt, LLM’lere sitenizin en önemli içeriklerini ve bağlamını daha iyi anlatmak için önerilen bir dosyadır. Özellikle dokümantasyon, yardım merkezi ve büyük bilgi yapılarında faydalı olabilir. Ama bugün için ne evrensel zorunlu standarttır ne de robots.txt’nin yerine geçer. Crawl kontrolü için robots.txt, URL kapsamı için sitemap.xml, Google AI görünürlüğü içinse normal SEO en iyi uygulamaları hâlâ ana araçlardır.
En doğru yaklaşım: llms.txt’yi “AI çağının robots.txt’si” gibi abartmadan, ama içerik rehberi olarak ciddiye alarak düşünmek. Eğer siten karmaşıksa ve içeriklerini ajanlara daha iyi anlatmak istiyorsan, temiz bir llms.txt dosyası denemeye değer. Ama bundan önce temel SEO, içerik kalitesi ve doğru crawler yönetimi çözülmüş olmalıdır.
